

Anúncio do espelhamento do banco de dados SQL do Azure no Fabric para visualização pública
Na era da transformação digital , da análise avançada e de um mundo impulsionado pela IA , os dados emergiram como o novo petróleo, impulsionando as empresas e impulsionando a tomada de decisões. Mas para que serve este óleo se não for refinado e estiver pronto para uso quando necessário? Além disso, gerenciar e ingerir dados em uma plataforma central para análise e IA é um processo caro e complicado. É aqui que entra em jogo a importância da replicação de dados quase em tempo real. Não se trata apenas de ter dados; trata-se de ter os dados certos no momento certo. Para enfrentar esses desafios, lançamos o Mirroring in Microsoft Fabric no Ignite’23 para visualização privada.
Microsoft anunciou recentemente a visualização pública do Espelhamento do Banco de Dados SQL do Azure, do Banco de Dados Azure Cosmos e das fontes de dados Snowflake no Fabric, uma maneira nova, simples e sem atrito de replicar um instantâneo desses bancos de dados de origem no Fabric OneLake em tabelas Delta que mantém os dados sincronizados quase em tempo real. Os principais benefícios que o espelhamento de bancos de dados no Fabric permite são:
- Custo total de propriedade reduzido com zero computação para replicar, juntamente com quantidades generosas (terabytes) de armazenamento com base no tamanho da capacidade.
- Código zero com ETL zero
- Tempo mais rápido para obter dados operacionais e informações para obter insights .
Este artigo explorará a importância do espelhamento do banco de dados SQL do Azure no Fabric, discutirá seus principais recursos e como ele pode transformar sua estratégia de dados.
Como funciona o espelhamento do banco de dados SQL do Azure no Fabric?
O espelhamento do Banco de Dados SQL do Azure no Fabric garante que seu banco de dados SQL transacional de origem esteja sempre atualizado e disponível no Fabric OneLake, fornecendo uma base sólida para relatórios, análises avançadas, IA e ciência de dados. Não há configuração complexa ou ETL para espelhamento. Você configura o espelho a partir da experiência do Fabric Data Warehousing fornecendo o servidor SQL do Azure e detalhes de conexão do banco de dados, fornecendo seleções sobre o que precisa ser espelhado no Fabric, todos os dados ou tabelas espelhadas qualificadas selecionadas pelo usuário. E, assim mesmo, o espelhamento está pronto para funcionar.
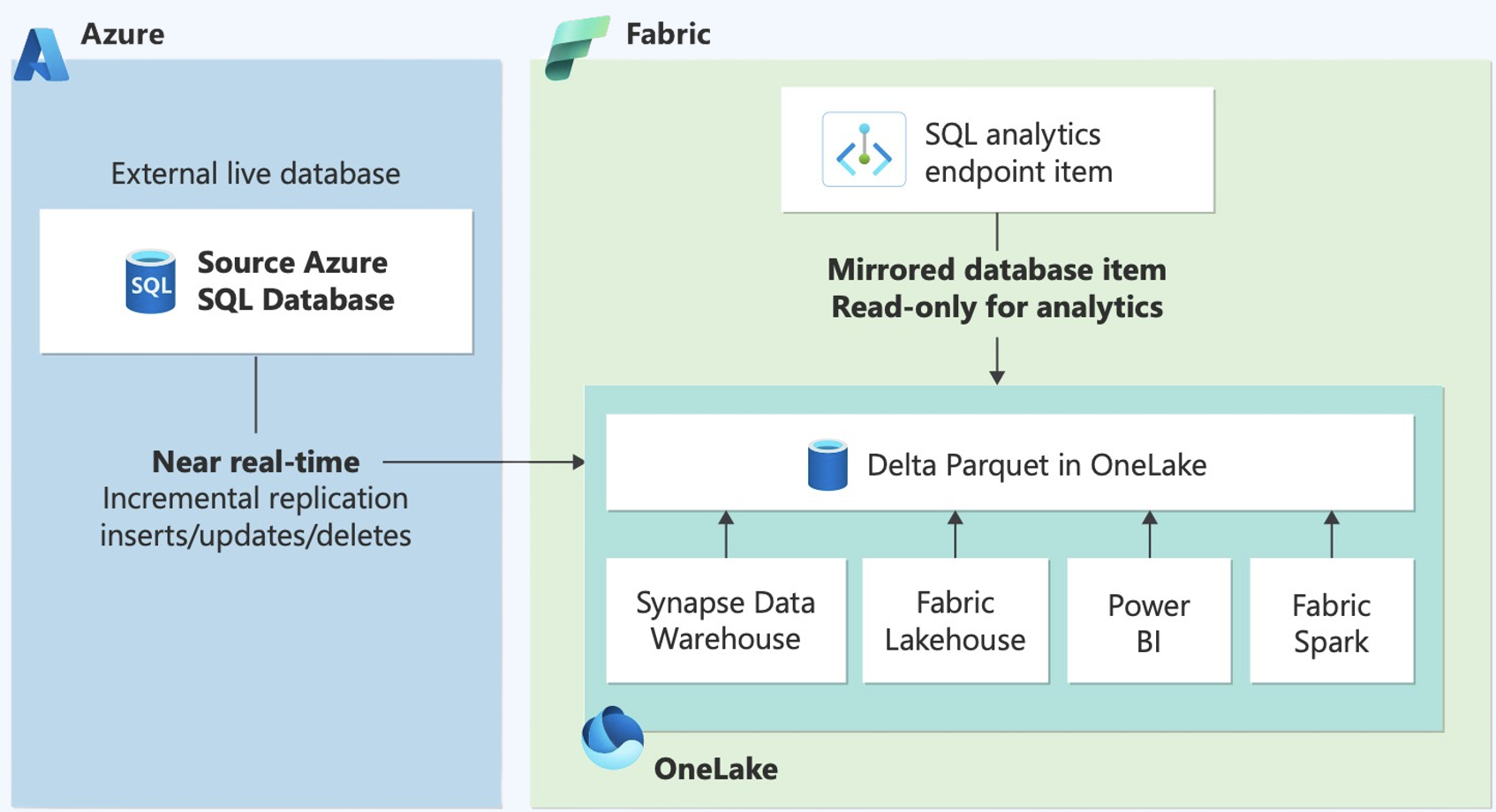
Espelhamento do banco de dados SQL do Azurecria um instantâneo inicial no Fabric OneLake, após o qual os dados são mantidos sincronizados quase em tempo real com cada transação quando uma nova tabela é criada/descartada ou os dados são atualizados.
Características principais
O espelhamento do Banco de Dados SQL do Azure é baseado na pilha Change Data Capture (CDC) do SQL, otimizada para arquitetura centrada em lago. O CDC armazena as alterações localmente no banco de dados, enquanto o Mirroring lê os dados do log de transações do banco de dados coletado e publica os dados alterados no armazenamento OneLake. Esses dados alterados são transformados em tabelas delta apropriadas que chegam ao Fabric OneLake. Além disso, colunas de adição/descarte de DDL também são suportadas em tabelas espelhadas ativamente.
Como administrador ou usuário do banco de dados SQL, você também pode verificar o status do espelhamento usando estes procedimentos armazenados públicos e visualizações de gerenciamento dinâmico:
- Para confirmar se a configuração de espelhamento do banco de dados SQL do Azure está habilitada corretamente, execute o seguinte procedimento armazenado público. As colunas principais a serem procuradas aqui são “table_name” e “state”. Qualquer valor da coluna “estado” além de “4” indica um problema potencial.
- executivo sp_help_change_feed;
- Se você estiver enfrentando problemas de espelhamento, execute as seguintes verificações no nível do banco de dados usando DMVs (Exibições de gerenciamento dinâmico) se as alterações de dados fluírem corretamente:
- SELECIONE * DE sys.dm_change_feed_log_scan_sessions;
- Se o DMV acima não mostrar nenhum progresso no processamento de alterações incrementais, execute a consulta abaixo para verificar se há algum problema relatado:
- SELECIONE * DE sys.dm_change_feed_errors;
Os dados espelhados também podem ser monitorados ativamente no Fabric, fornecendo mais insights sobre as operações de espelhamento e quando os dados espelhados foram atualizados pela última vez.
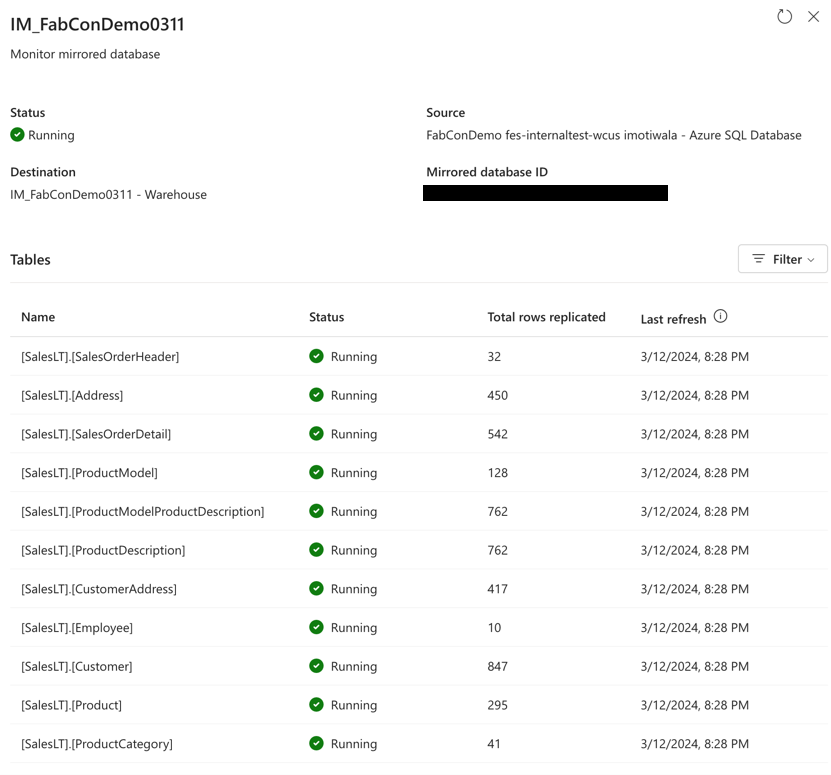
A partir daqui, os dados espelhados no formato delta estão prontos para consumo imediato em todas as experiências do Fabric e recursos como Power BI com o novo modo Direct Lake, Data Warehouse, Data Engineering, Lakehouse, banco de dados KQL, notebooks e copilotos funcionam instantaneamente.
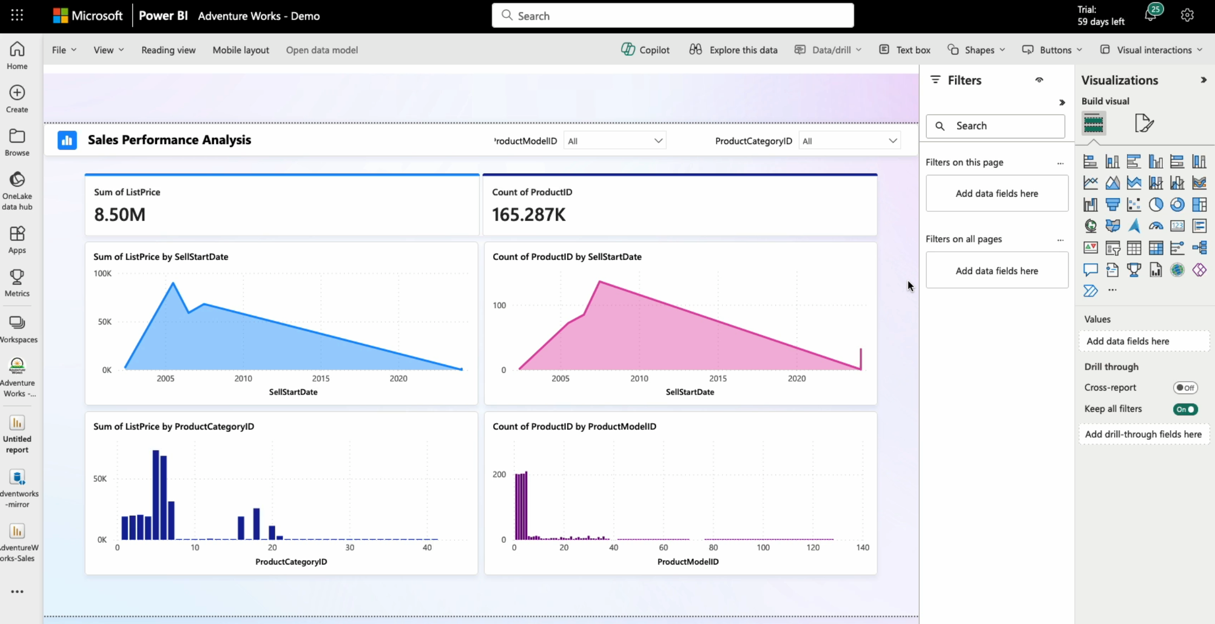
Modo Direct Lake do Power BI
O modo Direct Lake é um caminho rápido para carregar os dados do lago com capacidade de modelo semântico inovador para analisar volumes de dados muito grandes no Power BI. Como o modo Direct Lake também oferece suporte à leitura de tabelas Delta diretamente do OneLake, o banco de dados SQL espelhado está pronto para Power BI junto com o Copilot.
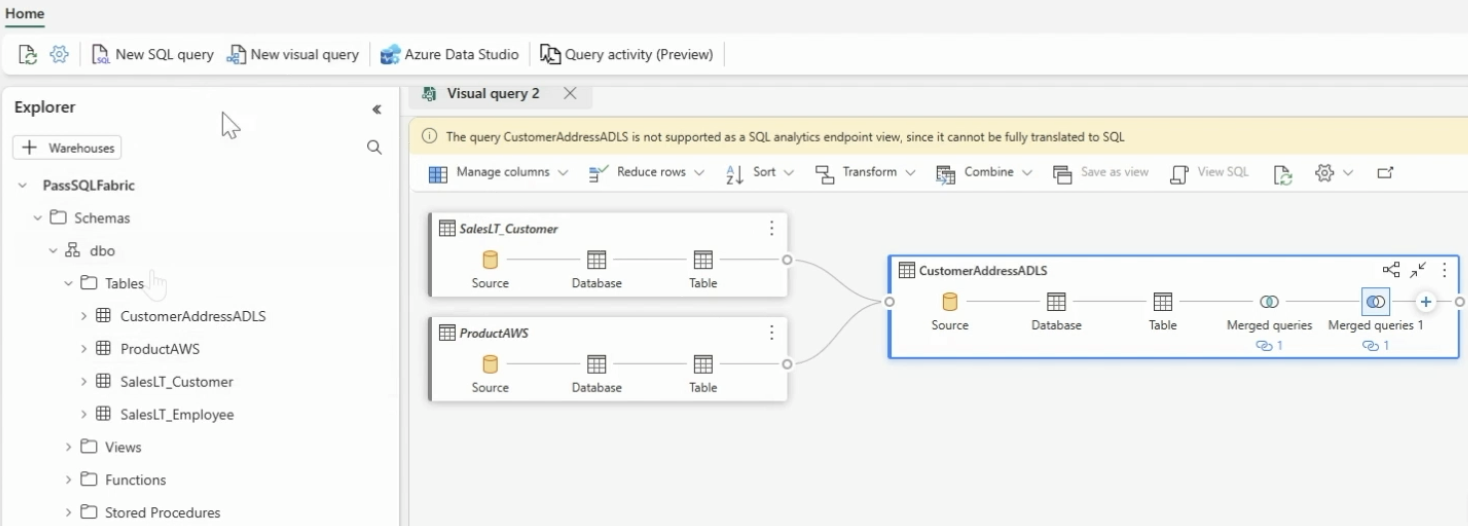
Junção cruzada de bancos de dados SQL espelhados, Lakehouse’s, Warehouses
Os dados em qualquer banco de dados espelhado (Azure SQL DB, Azure Cosmos DB ou Snowflake) podem ser unidos, além de permitir consultas em qualquer banco de dados, armazém ou lakehouse (seja como um atalho para AWS S3 ou ADLS Gen 2 etc.)
Explore insights de ciência de dados e engenharia de dados
Cientistas e engenheiros de dados podem trabalhar com dados SQL espelhados criados como atalhos no Lakehouse.
Resumo e comece.
Para resumir, o Espelhamento do Banco de Dados SQL do Azure no Fabric desempenha um papel crucial ao permitir análises e gerar insights a partir de dados ao:
- Oportunidade dos insights: garante que os dados mais recentes estejam disponíveis para análise. Isto permite que as empresas tomem decisões com base na situação mais atual, em vez de confiar em informações desatualizadas.
- Precisão aprimorada: o risco de discrepâncias entre a fonte e os dados replicados é significativamente reduzido, levando a análises mais precisas e insights confiáveis.
- Análise Preditiva e IA: Essencial para análises preditivas e modelos de IA que exigem os dados mais recentes para fazer previsões e decisões precisas.


